* Fix checkpointing GAN models (#1641)
* checkpoint sae step crash fix
* checkpoint save step crash fix
* Update gan.py
updated requested changes
* crash fix
* Fix the --model_name and --vocoder_name arguments need a <model_type> element (#1469)
Co-authored-by: Eren Gölge <erogol@hotmail.com>
* Fix Publish CI (#1597)
* Try out manylinux
* temporary removal of useless pipeline
* remove check and use only manylinux
* Try --plat-name
* Add install requirements
* Add back other actions
* Add PR trigger
* Remove conditions
* Fix sythax
* Roll back some changes
* Add other python versions
* Add test pypi upload
* Add username
* Add back __token__ as username
* Modify name of entry to testpypi
* Set it to release only
* Fix version checking
* Fix tokenizer for punc only (#1717)
* Remove redundant config field
* Fix SSIM loss
* Separate loss tests
* Fix BCELoss adressing #1192
* Make style
* Add durations as aux input for VITS (#1694)
* Add durations as aux input for VITS
* Make style
* Fix tts_tests
* Fix test_get_aux_input
* Make lint
* feat: updated recipes and lr fix (#1718)
- updated the recipes activating more losses for more stable training
- re-enabling guided attention loss
- fixed a bug about not the correct lr fetched for logging
* Implement VitsAudioConfig (#1556)
* Implement VitsAudioConfig
* Update VITS LJSpeech recipe
* Update VITS VCTK recipe
* Make style
* Add missing decorator
* Add missing param
* Make style
* Update recipes
* Fix test
* Bug fix
* Exclude tests folder
* Make linter
* Make style
* Fix device allocation
* Fix SSIM loss correction
* Fix aux tests (#1753)
* Set n_jobs to 1 for resample script
* Delete resample test
* Set n_jobs 1 in vad test
* delete vad test
* Revert "Delete resample test"
This reverts commit bb7c8466af.
* Remove tests with resample
* Fix for FloorDiv Function Warning (#1760)
* Fix for Floor Function Warning
Fix for Floor Function Warning
* Adding double quotes to fix formatting
Adding double quotes to fix formatting
* Update glow_tts.py
* Update glow_tts.py
* Fix type in download_vctk.sh (#1739)
typo in comment
* Update decoder.py (#1792)
Minor comment correction.
* Update requirements.txt (#1791)
Support for #1775
* Update README.md (#1776)
Fix typo in different and code sample
* Fix & update WaveRNN vocoder model (#1749)
* Fixes KeyError bug. Adding logging to dashboard.
* Make pep8 compliant
* Make style compliant
* Still fixing style
* Fix rand_segment edge case (input_len == seg_len - 1)
* Update requirements.txt; inflect==5.6 (#1809)
New inflect version (6.0) depends on pydantic which has some issues irrelevant to 🐸 TTS. #1808
Force inflect==5.6 (pydantic free) install to solve dependency issue.
* Update README.md; download progress bar in CLI. (#1797)
* Update README.md
- minor PR
- added model_info usage guide based on #1623 in README.md .
* "added tqdm bar for model download"
* Update manage.py
* fixed style
* fixed style
* sort imports
* Update wavenet.py (#1796)
* Update wavenet.py
Current version does not use "in_channels" argument.
In glowTTS, we use normalizing flows and so "input dim" == "ouput dim" (channels and length). So, the existing code just uses hidden_channel sized tensor as input to first layer as well as outputs hidden_channel sized tensor.
However, since it is a generic implementation, I believe it is better to update it for a more general use.
* "in_channels -> hidden_channels"
* Adjust default to be able to process longer sentences (#1835)
Running `tts --text "$text" --out_path …` with a somewhat longer
sentences in the text will lead to warnings like “Decoder stopped with
max_decoder_steps 500” and the sentences just being cut off in the
resulting WAV file.
This happens quite frequently when feeding longer texts (e.g. a blog
post) to `tts`. It's particular frustrating since the error is not
always obvious in the output. You have to notice that there are missing
parts. This is something other users seem to have run into as well [1].
This patch simply increases the maximum number of steps allowed for the
tacotron decoder to fix this issue, resulting in a smoother default
behavior.
[1] https://github.com/mozilla/TTS/issues/734
* Fix language flags generated by espeak-ng phonemizer (#1801)
* fix language flags generated by espeak-ng phonemizer
* Style
* Updated language flag regex to consider all language codes alike
* fix get_random_embeddings --> get_random_embedding (#1726)
* fix get_random_embeddings --> get_random_embedding
function typo leads to training crash, no such function
* fix typo
get_random_embedding
* Introduce numpy and torch transforms (#1705)
* Refactor audio processing functions
* Add tests for numpy transforms
* Fix imports
* Fix imports2
* Implement bucketed weighted sampling for VITS (#1871)
* Update capacitron_layers.py (#1664)
crashing because of dimension miss match at line no. 57
[batch, 256] vs [batch , 1, 512]
enc_out = torch.cat([enc_out, speaker_embedding], dim=-1)
* updates to dataset analysis notebooks for compatibility with latest version of TTS (#1853)
* Fix BCE loss issue (#1872)
* Fix BCE loss issue
* Remove import
* Remove deprecated files (#1873)
- samplers.py is moved
- distribute.py is replaces by the 👟Trainer
* Handle when no batch sampler (#1882)
* Fix tune wavegrad (#1844)
* fix imports in tune_wavegrad
* load_config returns Coqpit object instead None
* set action (store true) for flag "--use_cuda"; start to tune if module is running as the main program
* fix var order in the result of batch collating
* make style
* make style with black and isort
* Bump up to v0.8.0
* Add new DE Thorsten models (#1898)
- Tacotron2-DDC
- HifiGAN vocoder
Co-authored-by: manmay nakhashi <manmay.nakhashi@gmail.com>
Co-authored-by: camillem <camillem@users.noreply.github.com>
Co-authored-by: WeberJulian <julian.weber@hotmail.fr>
Co-authored-by: a-froghyar <adamfroghyar@gmail.com>
Co-authored-by: ivan provalov <iprovalo@yahoo.com>
Co-authored-by: Tsai Meng-Ting <sarah13680@gmail.com>
Co-authored-by: p0p4k <rajiv.punmiya@gmail.com>
Co-authored-by: Yuri Pourre <yuripourre@users.noreply.github.com>
Co-authored-by: vanIvan <alfa1211@gmail.com>
Co-authored-by: Lars Kiesow <lkiesow@uos.de>
Co-authored-by: rbaraglia <baraglia.r@live.fr>
Co-authored-by: jchai.me <jreus@users.noreply.github.com>
Co-authored-by: Stanislav Kachnov <42406556+geth-network@users.noreply.github.com>

🐸TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. 🐸TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
📰 Subscribe to 🐸Coqui.ai Newsletter
📢 English Voice Samples and SoundCloud playlist
📄 Text-to-Speech paper collection

💬 Where to ask questions
Please use our dedicated channels for questions and discussion. Help is much more valuable if it's shared publicly so that more people can benefit from it.
| Type | Platforms |
|---|---|
| 🚨 Bug Reports | GitHub Issue Tracker |
| 🎁 Feature Requests & Ideas | GitHub Issue Tracker |
| 👩💻 Usage Questions | Github Discussions |
| 🗯 General Discussion | Github Discussions or Gitter Room |
🔗 Links and Resources
| Type | Links |
|---|---|
| 💼 Documentation | ReadTheDocs |
| 💾 Installation | TTS/README.md |
| 👩💻 Contributing | CONTRIBUTING.md |
| 📌 Road Map | Main Development Plans |
| 🚀 Released Models | TTS Releases and Experimental Models |
🥇 TTS Performance
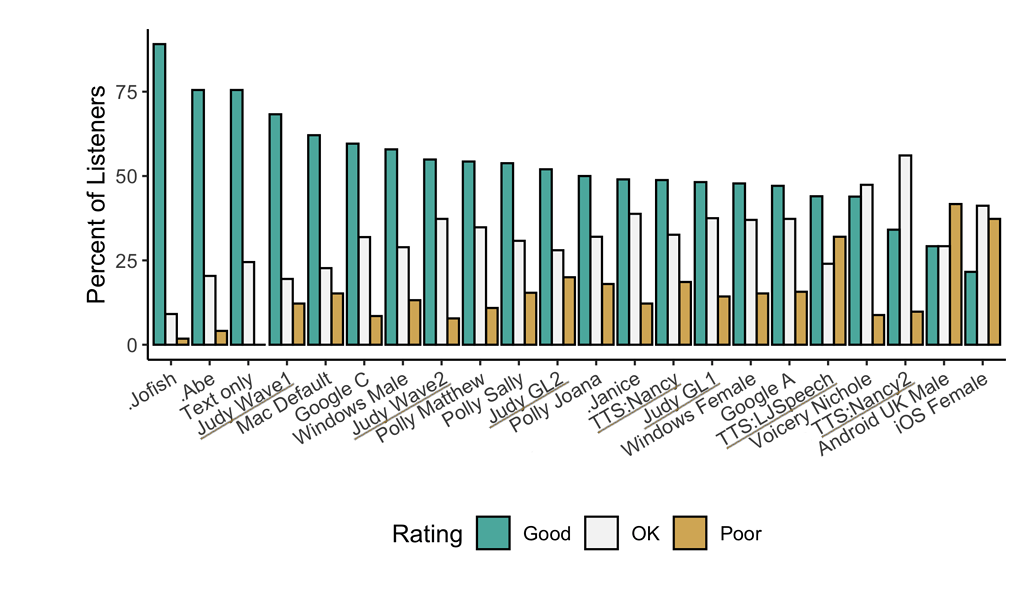
Underlined "TTS*" and "Judy*" are 🐸TTS models
Features
- High-performance Deep Learning models for Text2Speech tasks.
- Text2Spec models (Tacotron, Tacotron2, Glow-TTS, SpeedySpeech).
- Speaker Encoder to compute speaker embeddings efficiently.
- Vocoder models (MelGAN, Multiband-MelGAN, GAN-TTS, ParallelWaveGAN, WaveGrad, WaveRNN)
- Fast and efficient model training.
- Detailed training logs on the terminal and Tensorboard.
- Support for Multi-speaker TTS.
- Efficient, flexible, lightweight but feature complete
Trainer API. - Released and ready-to-use models.
- Tools to curate Text2Speech datasets under
dataset_analysis. - Utilities to use and test your models.
- Modular (but not too much) code base enabling easy implementation of new ideas.
Implemented Models
Text-to-Spectrogram
- Tacotron: paper
- Tacotron2: paper
- Glow-TTS: paper
- Speedy-Speech: paper
- Align-TTS: paper
- FastPitch: paper
- FastSpeech: paper
End-to-End Models
- VITS: paper
Attention Methods
- Guided Attention: paper
- Forward Backward Decoding: paper
- Graves Attention: paper
- Double Decoder Consistency: blog
- Dynamic Convolutional Attention: paper
- Alignment Network: paper
Speaker Encoder
Vocoders
- MelGAN: paper
- MultiBandMelGAN: paper
- ParallelWaveGAN: paper
- GAN-TTS discriminators: paper
- WaveRNN: origin
- WaveGrad: paper
- HiFiGAN: paper
- UnivNet: paper
You can also help us implement more models.
Install TTS
🐸TTS is tested on Ubuntu 18.04 with python >= 3.7, < 3.11..
If you are only interested in synthesizing speech with the released 🐸TTS models, installing from PyPI is the easiest option.
pip install TTS
If you plan to code or train models, clone 🐸TTS and install it locally.
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks] # Select the relevant extras
If you are on Ubuntu (Debian), you can also run following commands for installation.
$ make system-deps # intended to be used on Ubuntu (Debian). Let us know if you have a different OS.
$ make install
If you are on Windows, 👑@GuyPaddock wrote installation instructions here.
Use TTS
Single Speaker Models
-
List provided models:
$ tts --list_models -
Get model info (for both tts_models and vocoder_models):
-
Query by type/name: The model_info_by_name uses the name as it from the --list_models.
$ tts --model_info_by_name "<model_type>/<language>/<dataset>/<model_name>"For example:
$ tts --model_info_by_name tts_models/tr/common-voice/glow-tts$ tts --model_info_by_name vocoder_models/en/ljspeech/hifigan_v2 -
Query by type/idx: The model_query_idx uses the corresponding idx from --list_models.
$ tts --model_info_by_idx "<model_type>/<model_query_idx>"For example:
$ tts --model_info_by_idx tts_models/3
-
-
Run TTS with default models:
$ tts --text "Text for TTS" --out_path output/path/speech.wav -
Run a TTS model with its default vocoder model:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wavFor example:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --out_path output/path/speech.wav -
Run with specific TTS and vocoder models from the list:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --vocoder_name "<model_type>/<language>/<dataset>/<model_name>" --out_path output/path/speech.wavFor example:
$ tts --text "Text for TTS" --model_name "tts_models/en/ljspeech/glow-tts" --vocoder_name "vocoder_models/en/ljspeech/univnet" --out_path output/path/speech.wav -
Run your own TTS model (Using Griffin-Lim Vocoder):
$ tts --text "Text for TTS" --model_path path/to/model.pth --config_path path/to/config.json --out_path output/path/speech.wav -
Run your own TTS and Vocoder models:
$ tts --text "Text for TTS" --model_path path/to/config.json --config_path path/to/model.pth --out_path output/path/speech.wav --vocoder_path path/to/vocoder.pth --vocoder_config_path path/to/vocoder_config.json
Multi-speaker Models
-
List the available speakers and choose as <speaker_id> among them:
$ tts --model_name "<language>/<dataset>/<model_name>" --list_speaker_idxs -
Run the multi-speaker TTS model with the target speaker ID:
$ tts --text "Text for TTS." --out_path output/path/speech.wav --model_name "<language>/<dataset>/<model_name>" --speaker_idx <speaker_id> -
Run your own multi-speaker TTS model:
$ tts --text "Text for TTS" --out_path output/path/speech.wav --model_path path/to/config.json --config_path path/to/model.pth --speakers_file_path path/to/speaker.json --speaker_idx <speaker_id>
Directory Structure
|- notebooks/ (Jupyter Notebooks for model evaluation, parameter selection and data analysis.)
|- utils/ (common utilities.)
|- TTS
|- bin/ (folder for all the executables.)
|- train*.py (train your target model.)
|- distribute.py (train your TTS model using Multiple GPUs.)
|- compute_statistics.py (compute dataset statistics for normalization.)
|- ...
|- tts/ (text to speech models)
|- layers/ (model layer definitions)
|- models/ (model definitions)
|- utils/ (model specific utilities.)
|- speaker_encoder/ (Speaker Encoder models.)
|- (same)
|- vocoder/ (Vocoder models.)
|- (same)